Why Confluent Kafka Over Open-Source Apache Kafka?
Apache Kafka is a powerful open-source event streaming platform, but Confluent Kafka enhances it with enterprise-grade features that simplify operations, improve scalability, and provide a managed cloud experience. Here’s why organizations choose Confluent Kafka over vanilla Apache Kafka:
Key Advantages of Confluent Kafka
Building Your First Real-Time Pipeline with Confluent Cloud
Step 1: Sign Up & Set Up Confluent Cloud
Create an account on Confluent Cloud and deploy a Kafka cluster on your preferred cloud provider.
Step 2: Install Confluent CLI
curl -sL --http1.1 https://cnfl.io/install-cli | sh confluent loginStep 3: Create a Kafka Topic
confluent kafka topic create my-first-topicStep 4: Produce & Consume Messages
confluent kafka topic produce my-first-topic > Hello, Kafka! (Press Ctrl+D to send)Kafka 101: Key Concepts Explained
Apache Kafka is a distributed event streaming platform used for real-time data processing.
Real-World Example: Apache Kafka in an E-Commerce System
Imagine you run an online shopping platform like Amazon or Flipkart. You need to handle real-time events such as orders,
payments, and inventory updates efficiently. Here’s how Kafka helps:
Scenario: Order Processing in an E-Commerce Platform
When a customer places an order, multiple services need to act on it in real-time:
1️⃣ User Places an Order 🛍
The Order Service (Producer) sends an event "New Order Placed" to a Kafka topic (orders).
2️⃣ Payment Service Processes Payment 💳
The Payment Service (Consumer) reads the event from orders and processes the payment.
It then produces a new event "Payment Successful" to a Kafka topic (payments).
3️⃣ Inventory System Updates Stock 📦
The Inventory Service (Consumer) listens to the orders topic.
When an order is placed, it updates the stock and sends a "Stock Updated" event.
4️⃣ Shipping Service Starts Delivery 🚚
The Shipping Service (Consumer) listens to the payments topic.
When payment is successful, it initiates the delivery process.
Kafka Flow in this Example
🔹 Producers: Order Service, Payment Service, Inventory Service
🔹 Kafka Topics: orders, payments, inventory-updates, shipping
🔹 Consumers: Payment Service, Inventory Service, Shipping Service
Why Use Kafka?
✅ Real-time data streaming – Events are processed instantly.
✅ Decoupled Microservices – Services communicate via Kafka without direct dependencies.
✅ Fault Tolerance & Scalability – Can handle millions of transactions smoothly.
This is how Kafka powers real-time e-commerce systems!
Deep Dives into Core Components
Mastering ksqlDB: Real-Time Stream Processing with SQL
ksqlDB allows you to process Kafka streams using SQL, making real-time analytics easier.
🔹 Key Use Cases
1️⃣ Aggregations (Count, Sum, Avg, etc.) 📊
Monitor active users per minute:
CREATE TABLE active_users AS
SELECT user_id, COUNT(*) AS login_count
FROM logins
WINDOW TUMBLING (SIZE 1 MINUTE)
GROUP BY user_id;
Merge user orders with payment details:
CREATE STREAM enriched_orders AS
SELECT o.order_id, o.user_id, p.payment_status
FROM orders o
JOIN payments p
ON o.order_id = p.order_id;Flag high-value transactions (above $10,000):
CREATE STREAM suspicious_txn AS
SELECT * FROM transactions
WHERE amount > 10000;✔ No Java coding – SQL-based processing
✔ Real-time analytics at scale
✔ Ideal for fraud detection, monitoring, and ETL
ksqlDB simplifies stream processing – making Kafka truly real-time!
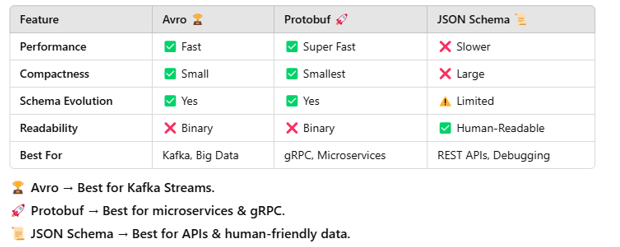
Schema Registry Deep Dive: Avro vs. Protobuf vs. JSON Schema
Schema Registry ensures consistent, structured, and evolvable data in Kafka by enforcing schemas for message serialization. The three most common formats are Avro, Protobuf, and JSON Schema.

Kafka Connect: Building Scalable ETL Pipelines to Snowflake, S3, and Elasticsearch
Kafka Connect simplifies ETL (Extract, Transform, Load) pipelines, allowing real-time data streaming between Kafka and external systems like Snowflake, S3, or Elasticsearch.
1️⃣ Setting Up Kafka Connect✅ Deploy Kafka Connect (Standalone or Distributed Mode).
✅ Use pre-built connectors from Confluent Hub.
✅ Configure connectors using JSON files.
2️⃣ Snowflake Sink Connector (Real-Time Data Warehousing)
🔹 Streams Kafka data directly to Snowflake for analytics.
🔹 Supports Avro, JSON, or Protobuf formats.
Sample Configuration (snowflake-sink.json):
{
"name": "snowflake-sink-connector",
"config": {
"connector.class": "com.snowflake.kafka.connector.SnowflakeSinkConnector",
"topics": "orders",
"snowflake.url.name": "https://your-account.snowflakecomputing.com",
"snowflake.user.name": "your-user",
"snowflake.private.key": "your-private-key",
"tasks.max": "3"
}
}3️⃣ Amazon S3 Sink Connector (Data Archiving & Analytics) 🗄
🔹 Streams Kafka data into Amazon S3 buckets.
🔹 Useful for batch processing, backups, and machine learning.
Sample Configuration (s3-sink.json):
{
"name": "s3-sink-connector",
"config": {
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"topics": "logs",
"s3.bucket.name": "my-kafka-data",
"format.class": "io.confluent.connect.s3.format.json.JsonFormat",
"tasks.max": "2"
}
}Deploy:confluent connect create --config s3-sink.json
4️⃣ Elasticsearch Sink Connector (Real-Time Search & Analytics)
🔹 Streams Kafka data to Elasticsearch for fast querying.
🔹 Ideal for log analytics, monitoring, and full-text search.
Sample Configuration (es-sink.json):
{
"name": "elasticsearch-sink-connector",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"topics": "user-activity",
"connection.url": "http://elasticsearch:9200",
"type.name": "_doc",
"tasks.max": "2"
}
}Optimizing Kafka Connect Performance
✔ Use multiple tasks (tasks.max) for parallel processing.
✔ Batch messages (batch.size) to optimize throughput.
✔ Use Avro or Protobuf for efficient serialization.
✔ Enable schema evolution with Schema Registry.
Hot Topics in 2023:
Serverless Kafka (Confluent Cloud).
Generative AI + real-time data .
Data contracts and governance with Schema Registry.
Conclusion
Apache Kafka is the backbone of real-time data streaming. With Confluent Kafka, businesses can scale event-driven architectures effortlessly.
Next Steps: Start your Kafka journey today with Confluent Cloud and transform the way you handle real-time data!



